一次k8s容器内存oom-kill问题研究
问题现象
公司最近逐步推进JRE8升级到JRE17,在解决了升级初期的一些库升级、兼容问题后,大部分应用容器趋于稳定。 随着升级的服务越来越多,最近发现部分升级JRE17服务的容器有零星的注册中心健康检查失败报错,涉及到多个服务的多个节点,虽然在报错一次后恢复正常,但是这个现象是以前这些服务从来没有出现过的,基于不放过任何一个疑点的原则,有必要调查一下原因。
2025-05-28 10:01:28.330
标题:断开连接(异常)
应用:xxx (default:-1)
实例:10.100.1.1:8080初步定位
- 最初的报错是注册中心发出,查看注册中心的事件日志确认,报错是因为注册中心调用容器的
/actuator/health接口时,http连接异常断开 - 一般来说,http连接异常断开有几种可能
- 网络异常:丢包,延迟,阻塞
- 调用方超时主动断开:连接超时、读超时
- 被调用方响应性能异常:建连失败、响应超时、tcp reset
- 排查异常容器的核心指标,主要是worker线程数量,内网指标tcp丢包率等,排除了上述常见可能性后,再查看容器的事件日志,发现问题容器都有被k8s重启的相关事件,且时间点与注册中心异常告警一致,初步认定容器被k8s重启是导致注册中心告警的原因
- 排查k8s日志,发现对应时间点,容器进程内存占用超过了k8s配置文件对requests.limit的限制,最终导致k8s强制关闭容器
- 排查容器内存指标,能看到容器的物理内存在30%~40%左右,但是容器内存持续保持在100%接近1分钟


经过上述的快速排查,引入了几个问题
问题1: 物理内存和容器内存为什么差距这么大? 问题2: 容器内存具体是什么在占用?
解决上述问题需要了解进程的内存统计以及CGroup的内存统计,有必要进行一定的知识补全
内存统计知识
Linux系统内存分布
Linux系统内存,除系统启动过程中消耗的内存外,剩余内存为系统使用内存,一般使用free命令来查看系统整体的内存占用
$ free -mh
total used free shared buff/cache available
Mem: 31Gi 15Gi 235Mi 194Mi 15Gi 15Gi
- total:系统物理内存,在启动时会被启动过程,kdump等组件用掉一部分,剩下的是内核和应用程序可以使用的内存,也是free命令中输出的total字段,比物理内存略小一些
- free:完全未分配的内存
- buff/cache:由系统管理的缓存
- used:total - free - buffers - cache
- shared:Shmem共享内存页(对应共享匿名映射、tmpfs、memfd等场景),同时也会算到cache里
从第2点可以推断出:total = used + buff/cache + free
其中free很好理解,就是剩余未分配的物理内存,used是减出来的,所以关键是理解buffers和cache内存。
关于buffers/cache
$ man free
...
buffers
Memory used by kernel buffers (Buffers in /proc/meminfo)
cache Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)
buff/cache
Sum of buffers and cache
...可以看出
- buffers:内核缓冲区用到的内存【Memory used by kernel buffers (Buffers in /proc/meminfo)】
- cache:PageCache和 slab【Memory used by the page cache and slabs (Cached and SReclaimable in /proc/meminfo)】
$ man proc
...
Buffers %lu
Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20 MB or so).
Cached %lu
In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
SReclaimable %lu (since Linux 2.6.19)
Part of Slab, that might be reclaimed, such as caches.从下面的图片可以看出,buffer位于相对底层,是文件系统和物理磁盘(块设备)之间的缓冲区,而PageCache是系统内核和文件系统之间的缓冲区。
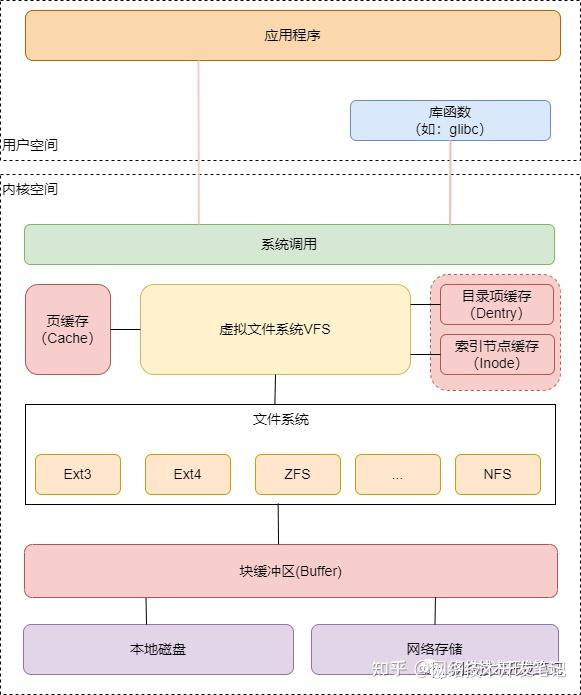
另外,linux内核使用 Slab 机制,管理文件系统的目录项和索引节点的缓存。Slab 包括两部分,其中的可回收部分,是指可以被回收的内核内存,包括目录项(dentry) 和索引节点( inode )的缓存等,用 SReclaimable 记录;而不可回收部分,用 SUnreclaim 记录。
系统Cache/Buffer回收策略
- 系统内存不足时,会尝试异步回收cache>同步回收cache,如果仍旧不足,触发oom
- 可以通过写入
/proc/sys/vm/drop_caches文件来触发系统回收,其中echo 1 > /proc/sys/vm/drop_caches:释放Cache的干净页echo 2 > /proc/sys/vm/drop_caches:释放slabecho 1 > /proc/sys/vm/drop_caches:释放Cache和slab
- 如果想回收Cache的脏页,需要先执行sync,写入磁盘后变为干净页才可以回收
进程内存构成
对于一个进程来说,与之相关联的内存可以分为2大类
- 基于文件的内存页,file-backed-memory:基于文件的内存页,注意,由于linux一切皆是文件的特性,这里的文件除了存储在磁盘上的文件,还包含了一些其他的特殊场景
- 基于磁盘文件的映射:比如BufferedIO
- 基于MMAP读取文件:比如数据库一般会直接使用mmap来管理内存和磁盘文件的一致性,mmap方式的优点是避免了bufferedIO的
- 共享匿名映射:基于/tmpfs的映射,理论上也属于mmap的一种,区别是Linux系统下/tmpfs通常对应物理内存空间而不是磁盘,常用于父子进程通信
- 匿名内存页,anno-rss:对应通过malloc方法申请的内存

常见内存统计工具
cgroup内存统计
可能是下面的两个路径之一:
/sys/fs/cgroup/memory/memory.stat/sys/fs/cgroup/memory.stat
$ cat /sys/fs/cgroup/memory/memory.stat
cache 2042019840
rss 817131520
...
mapped_file 545329152
...
inactive_file 490184704
active_file 949952512
...
total_cache 2042019840
total_rss 817131520
...
total_inactive_file 490184704
total_active_file 949952512
...如上,省略了部分项,剩下需要关注的
- rss: 匿名内存总和
- cache: 类似free命令的cache/buffer,对应所有的file-backend内存
- mapped_file: 包含所有mmap的匿名内存(MAP_ANONYMOUS),包含tmpfs/shmem
- active_file: 除匿名内存外的PageCache,注意cgroup统计的是此进程组使用过的所有的文件句柄对应的PageCache,包含打开和关闭(但未被回收的内存页)
- inactive_file:active_file中标记为inactive的内存页
working_set的计算公式:working_set = rss + cache - inactive_file
/proc/{pid}/status
/proc文件夹下的内容是进程对应的
$ cat /proc/1/status
......
VmPeak: 108647580 kB
VmSize: 108516356 kB
VmLck: 0 kB
VmPin: 0 kB
VmHWM: 6072292 kB
VmRSS: 1714428 kB
RssAnon: 591256 kB
RssFile: 18260 kB
RssShmem: 1104912 kB
VmData: 107086612 kB
VmStk: 152 kB
VmExe: 4 kB
VmLib: 22832 kB
VmPTE: 4908 kB
VmSwap: 0 kB
Threads: 370
......其中Vm前缀的内存对应虚拟内存相关指标,由于容器环境的一些限制,可能显示的是宿主机的值,仅供参考,重点关注RssAnon,RssFile和RssShmem这几个值,其中 RssAnon为匿名内存,RssFile为文件内存(不包含匿名文件映射),RssShmem为共享文件内存
VmSize: 虚拟内存大小。 整个进程使用虚拟内存大小,是VmLib, VmExe, VmData, 和 VmStk的总和。
VmLck: 虚拟内存锁。 进程当前使用的并且加锁的虚拟内存总数
VmRSS: 虚拟内存驻留集合大小。 这是驻留在物理内存的一部分。它没有交换到硬盘。它包括代码,数据和栈。 VmRSS = RssAnon + RssFile + RssShmem
VmData: 虚拟内存数据。 堆使用的虚拟内存。
VmStk: 虚拟内存栈 栈使用的虚拟内存
VmExe: 可执行的虚拟内存 可执行的和静态链接库所使用的虚拟内存
VmLib: 虚拟内存库 动态链接库所使用的虚拟内存
/proc/meminfo
可以根据文件/proc/meminfo的内容来查看整个系统当前的内存占用,free命令的数据也是从这个文件提取再加工的
$ cat /proc/meminfo
MemTotal: 32779612 kB
MemFree: 3916296 kB
MemAvailable: 30638252 kB
Buffers: 855164 kB
Cached: 24187724 kB
SwapCached: 16 kB
Active: 3009196 kB
Inactive: 23054352 kB
Active(anon): 1034236 kB
Inactive(anon): 1388 kB
Active(file): 1974960 kB
Inactive(file): 23052964 kB
Unevictable: 1876 kB
Mlocked: 0 kB
SwapTotal: 2097148 kB
SwapFree: 2096124 kB
Zswap: 0 kB
Zswapped: 0 kB
Dirty: 156 kB
Writeback: 0 kB
AnonPages: 1022560 kB
Mapped: 587176 kB
Shmem: 14960 kB
KReclaimable: 2162372 kB
Slab: 2523328 kB
SReclaimable: 2162372 kB
SUnreclaim: 360956 kB
KernelStack: 13600 kB
PageTables: 28620 kB
SecPageTables: 0 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 18486952 kB
Committed_AS: 6725936 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 106192 kB
VmallocChunk: 0 kB
Percpu: 15456 kB
HardwareCorrupted: 0 kB
AnonHugePages: 0 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
FileHugePages: 0 kB
FilePmdMapped: 0 kB
Unaccepted: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 604784 kB
DirectMap2M: 17135616 kB
DirectMap1G: 15728640 kB掌握上述基本知识后,尝试分析解决最初的内存问题,基本思路是先尝试复现,在复现的基础上收集内存指标,通过观察、对比和实验确定问题点,然后进行修复,最后观察修复效果并复盘
问题复现
- 问题发生在生产环境,尝试在测试环境寻找有相同问题的应用,
- 范围:最近7天内,应用重启次数大于1。
- 结果没有找到
- 考虑到题跟Java容器的内存相关,怀疑是否跟JVM有关,尝试写代码mock堆内存压力升高的场景,看看是否可以复现
模拟堆内存压力
思路: 通过代码来占用较大量的堆内存,观察working_set在此前后的变化,判断问题是否产生在堆上。
首先观察容器初始的状态
初始状态
- 从指标监测看到,物理内存使用量是0.46G左右,WorkingSet使用量为0.88G,有0.88-0.46=0.42G的GAP
- 命令行查看内存占用明细
$ cat /sys/fs/cgroup/memory/memory.usage_in_bytes
966750208 ≈ 0.9G
$ cat /sys/fs/cgroup/memory/memory.stat
cache 461389824 ≈ 0.44G
rss 512860160 ≈ 0.48G
...
mapped_file 350171136 ≈ 0.33G
...
inactive_anon 341835776
active_anon 546357248
inactive_file 294912
active_file 85704704 ≈ 0.081G
...可以看到堆内存(RSS物理内存)占用0.48G,PageCache约为0.08G,匿名内存页约为0.33G,乍看上去一切正常
提升堆占用后的状态
相关代码如下,每次调用会占用x MB大小的堆内存,且线程睡眠一定时间内不会释放或者GC
@GetMapping("/increase-memory")
public JsonResult<Boolean> increaseMemory(@RequestParam("x") int x, @RequestParam("s") long s) throws InterruptedException {
byte[] bytes = new byte[1024 * 1024 * x];
bytes[0] = 1;
Thread.sleep(s);
System.out.println(bytes[0]);
return JsonResult.success();
}调用参数:x = 300,s=1000000,连续调用3次后,理论上会在对上分配300*3=900M内存,1000秒后释放。
GC前内存占用:
$ cat /sys/fs/cgroup/memory/memory.stat
cache 1406787584 ≈ 1.31G
rss 495648768 ≈ 0.46G
rss_huge 0
mapped_file 1304526848 ≈ 1.21G
...
inactive_file 10440704
active_file 85626880
...
$ unset JAVA_TOOL_OPTIONS;jhsdb jmap --heap --pid 1
Attaching to process ID 1, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 17.0.10+11-LTS-240
using thread-local object allocation.
ZGC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1933574144 (1844.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 17592186044415 MB
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 22020096 (21.0MB)
CompressedClassSpaceSize = 218103808 (208.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
ZHeap used 1140M, capacity 1250M, max capacity 1844MGC后
$ cat /sys/fs/cgroup/memory/memory.stat
cache 1617858560 ≈ 1.5G
rss 525516800 ≈ 0.48G
...
mapped_file 1476038656 ≈ 1.37G
...
inactive_file 10690560
active_file 107704320 ≈ 0.1G
$ unset JAVA_TOOL_OPTIONS;jhsdb jmap --heap --pid 1
Attaching to process ID 1, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 17.0.10+11-LTS-240
using thread-local object allocation.
ZGC with 2 thread(s)
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 1933574144 (1844.0MB)
NewSize = 1363144 (1.2999954223632812MB)
MaxNewSize = 17592186044415 MB
OldSize = 5452592 (5.1999969482421875MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 22020096 (21.0MB)
CompressedClassSpaceSize = 218103808 (208.0MB)
MaxMetaspaceSize = 268435456 (256.0MB)
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
ZHeap used 286M, capacity 1430M, max capacity 1844M可以看到,相比较初始状态,rss并没有明显变化,反而cache和mapped_file增加了约900M,引入了新问题:ZGC的堆分配对应cgroup的cache(mapped_file)部分,与以往JDK8不一致(JDK8堆分配在RSS),结合前面的内存分布知识,mapped_file属于cache的一部分,难道ZGC的堆不在匿名内存里?
ZGC堆内存分配区域研究
在查询资料解决上述问题的同时,我们也观察了同样的场景在G1下的表现,与预期一致,堆占用提升,并不会导致cache部分的提升,且RSS部分的数量约等于配置的堆上限,可见G1收集器堆内存对应RSS部分。
进一步的查阅资料后发现,ZGC的堆内存,底层使用memfd_create方法,具体如下
int ZPhysicalMemoryBacking::create_mem_fd(const char* name) const {
// ...
// Create file
const int extra_flags = ZLargePages::is_explicit() ? (MFD_HUGETLB | MFD_HUGE_2MB) : 0;
const int fd = ZSyscall::memfd_create(filename, MFD_CLOEXEC | extra_flags);
// ...
log_info_p(gc, init)("Heap Backing File: /memfd:%s", filename);
return fd;
}查阅Linux的man page看,memfd_create方法创建一个匿名文件fd,再使用mmap方法来二次加载到虚拟内存中,所以这部分内存属于mmap内存。
MEMFD_CREATE(2) Linux Programmer's Manual MEMFD_CREATE(2)
NAME
memfd_create - create an anonymous file
SYNOPSIS
#define _GNU_SOURCE /* See feature_test_macros(7) */
#include <sys/mman.h>
int memfd_create(const char *name, unsigned int flags);
DESCRIPTION
memfd_create() creates an anonymous file and returns a file descriptor that refers to it. The file behaves like a regular file, and so can be modified,
truncated, memory-mapped, and so on. However, unlike a regular file, it lives in RAM and has a volatile backing storage. Once all references to the
file are dropped, it is automatically released. Anonymous memory is used for all backing pages of the file. Therefore, files created by memfd_create()
have the same semantics as other anonymous memory allocations such as those allocated using mmap(2) with the MAP_ANONYMOUS flag通过进程的smaps命令来验证上述内存
$ cat /proc/1/maps |grep heap
40000000000-40000600000 rw-s 16200000 00:04 4098814597 /memfd:java_heap (deleted)
40000600000-40001800000 rw-s 16a00000 00:04 4098814597 /memfd:java_heap (deleted)
40001800000-40001a00000 rw-s 17e00000 00:04 4098814597 /memfd:java_heap (deleted)
40001a00000-40001e00000 rw-s 18200000 00:04 4098814597 /memfd:java_heap (deleted)
40002600000-40002a00000 rw-s 02600000 00:04 4098814597 /memfd:java_heap (deleted)
40002e00000-40003000000 rw-s 02e00000 00:04 4098814597 /memfd:java_heap (deleted)
40004800000-40004a00000 rw-s 04800000 00:04 4098814597 /memfd:java_heap (deleted)至此,ZGC的堆内存分配区域理解完成,但是,即使所有的PageCache+RSS,也就2.5G左右,离问题触发时4G的阈值相去甚远,剩余的working_set内存都在哪里?要解决这个问题,还是希望能有一个相对稳定的复现流程。
考虑到问题服务在JDK8上没有问题,那问题是否跟GC过程有关?下一步模拟下大量GC的过程,看看是否可以复现。
尝试大量触发GC
思路:在堆内存占用已经很大的前提下,尝试申请内存、使用内存、释放的循环。
@GetMapping("/trigger-fullgc")
public JsonResult<Boolean> triggerFullGC(@RequestParam("m") int m, @RequestParam("s") long s,
@RequestParam("t") int times) throws InterruptedException {
for (int i = 0; i < times; i++) {
// 循环创建内存,使用,释放
triggerFullGC(m, s);
}
return JsonResult.success();
}
private void triggerFullGC(int m, long s) throws InterruptedException {
byte[] bytes = new byte[1024 * 1024 * m];
bytes[0] = 1;
Thread.sleep(s);
System.out.println(bytes[0]);
}
@GetMapping("/increase-memory")
public JsonResult<Boolean> increaseMemory(@RequestParam("m") int m, @RequestParam("s") long s) throws InterruptedException {
// 一次性占用大量内存
byte[] bytes = new byte[1024 * 1024 * m];
bytes[0] = 1;
Thread.sleep(s);
System.out.println(bytes[0]);
return JsonResult.success();
}最终没有复现线上的问题,堆上的内存分配-释放循环,不会导致PageCache进一步提升,说明堆内存不是导致内存超限的原因。
复现的过程陷入僵局,睡了一觉以后,考虑思路做一个转换,考虑寻找接近复现的服务
寻找问题相近的服务
测试环境尝试寻找接近超限的容器,查询条件为working_set>3G且容器内存=4G,找到多个服务,选择典型且个人熟悉的服务观察。
查看当前cgroup内存状态如下,可以看到active_file为1.13G左右,偏高
$ cat /sys/fs/cgroup/memory/memory.stat
cache 2944737280 = 2.74G
rss 1069068288 = 0.99G
rss_huge 448790528
mapped_file 1361448960 = 1.26G
swap 0
pgpgin 33070432
pgpgout 32208029
pgfault 52502832
pgmajfault 1
inactive_anon 1421869056
active_anon 1083723776
inactive_file 295665664 ≈ 0.27G
active_file 1212522496 = 1.13G
unevictable 0
hierarchical_memory_limit 4294967296
hierarchical_memsw_limit 4294967296
total_cache 2944737280
total_rss 1069068288
total_rss_huge 448790528
total_mapped_file 1361448960
total_swap 0
total_pgpgin 0
total_pgpgout 0
total_pgfault 0
total_pgmajfault 0
total_inactive_anon 1421869056
total_active_anon 1083723776
total_inactive_file 295665664
total_active_file 1212522496
total_unevictable 0从理论上分析,active_file对应的文件的page_cache,大部分为jar包,lib.so,以及少量IO对应的socket,前者启动时就加载,在前面分析过程中冷启动可以看出,大概在500M左右,远小于1.13G,这里有问题,需要进一步分析细节。
问题服务PageCache分析
掏出各路AI来分析了一下,AI推荐PageCache从下列文件中获得
cat /proc/1/smaps使用AI快速编写了一个排序脚本,发现smaps排在前面的是堆内存块,且rss总数只有500M,不对,需要重新寻找。 再次通过AI搜索,找到一个可以查询page_cache的库:pgcacher
git clone https://github.com/rfyiamcool/pgcacher
make install
chmod a+x pgcacher
./pgcacher -pid 1上述运行以后的结果如文件:output
$ ./pgcacher -pid 1
+----------------------------------------------------------------------------------------+----------------+-------------+----------------+-------------+---------+
| Name | Size │ Pages │ Cached Size │ Cached Pages│ Percent │
|----------------------------------------------------------------------------------------+----------------+-------------+----------------+-------------+---------|
| /logs/skywalking.log | 270.131M | 69154 | 270.131M | 69154 | 100.000 |
| /usr/lib/jvm/jdk-17-oracle-x64/lib/modules | 121.238M | 31037 | 121.238M | 31037 | 100.000 |
| /data/logs/serviceA/access.log | 104.286M | 26698 | 104.286M | 26698 | 100.000 |
| /data/logs/gc2025-05-22_16-02-46.log | 91.887M | 23524 | 91.231M | 23356 | 99.286 |
| /data/logs/serviceA/warn.log | 89.316M | 22866 | 89.316M | 22866 | 100.000 |
| /opt/serviceA.jar | 188.411M | 48234 | 78.932M | 20207 | 41.894 |
| /data/logs/serviceA/error.log | 61.573M | 15763 | 61.573M | 15763 | 100.000 |
| /data/logs/serviceA/info.log | 32.952M | 8436 | 32.952M | 8436 | 100.000 |
| /usr/lib/jvm/jdk-17-oracle-x64/lib/server/libjvm.so | 21.869M | 5599 | 21.869M | 5599 | 100.000 |
......
......
|----------------------------------------------------------------------------------------+----------------+-------------+----------------+-------------+---------|
│ Sum │ 1.025G │ 268758 │ 939.132M │ 240488 │ 89.481 │
+----------------------------------------------------------------------------------------+----------------+-------------+----------------+-------------+---------+pageCache总计有1G左右,与上面的统计对应,能看到最大的是skywalking.log文件,文件270M,占用的cache也约为这个值,需要优化。 顺手打开文件看看内容,可以看到有大量的报错,需要解决。同时,应用的info、warn等日志也比较大,有优化空间。
根因分析
应用打开的文件有一些大文件,打开文件对应需要使用PageCache,占用内存
- skywaking-log 最大300M
- access-log 最大512M
- 业务日志,4个级别,配置单文件最大为128M
仅上述这部分PageCahce加和极限情况下能达到(128M*4+300M+512M)=1.3G,加上目前启动固定内存占用有
- 2G:堆
- 0.786G:元空间+CodeCache
- 0.4G:依赖包固定的PageCache(so库,jar包, GC Log) 加起来=4.4G,考虑到还有网络I/O等的内存占用,所以很多情况下会导致OOM
解决方案
- 解决探针日志skywalking-api.log中对应的异常
- skywalking-api.log文件过大,需要缩小或进行chunk
- 日志:access.log 过大,需要进行chunk
- 应用日志:warn.log,info.log等,单文件过大,需要调整:
<maxFileSize>128MB</maxFileSize>修改应用配置
效果
测试环境验证:上述解决方案上线后,应用的working_set平均降低30%
复盘
事后看,在最初尝试复现问题时,走了一些弯路,最后也没有成功复盘,最终是通过寻找问题相近服务破局,后续可以更灵活的调整问题切入的视角和思路。
评论