JDK源码-HashMap增删与扩容
1. 构造方法
public HashMap(int initialCapacity, float loadFactor)
- initialCapacity:初始容量,传入时,threshold(下次扩容阈值)为tableSizeFor(initialCapacity)即向上找最接近的2的整数次幂,不传入默认为0,在这种情况下,在第一次put元素时,table为空不够用导致resize(),resise后capacity为默认值16,threshold为16*loadFactor;
- loadFactor:负载因子,当table内存储数据达到此比例后,经验推断hash碰撞的可能性会大大提高,因此需要进行扩容,默认0.75,此属性为protect变量,修改需要新写HashMap的子类
2. 增删改
2.1. 增
实际调用putVal方法来进行新增操作:
2.1.1 流程图
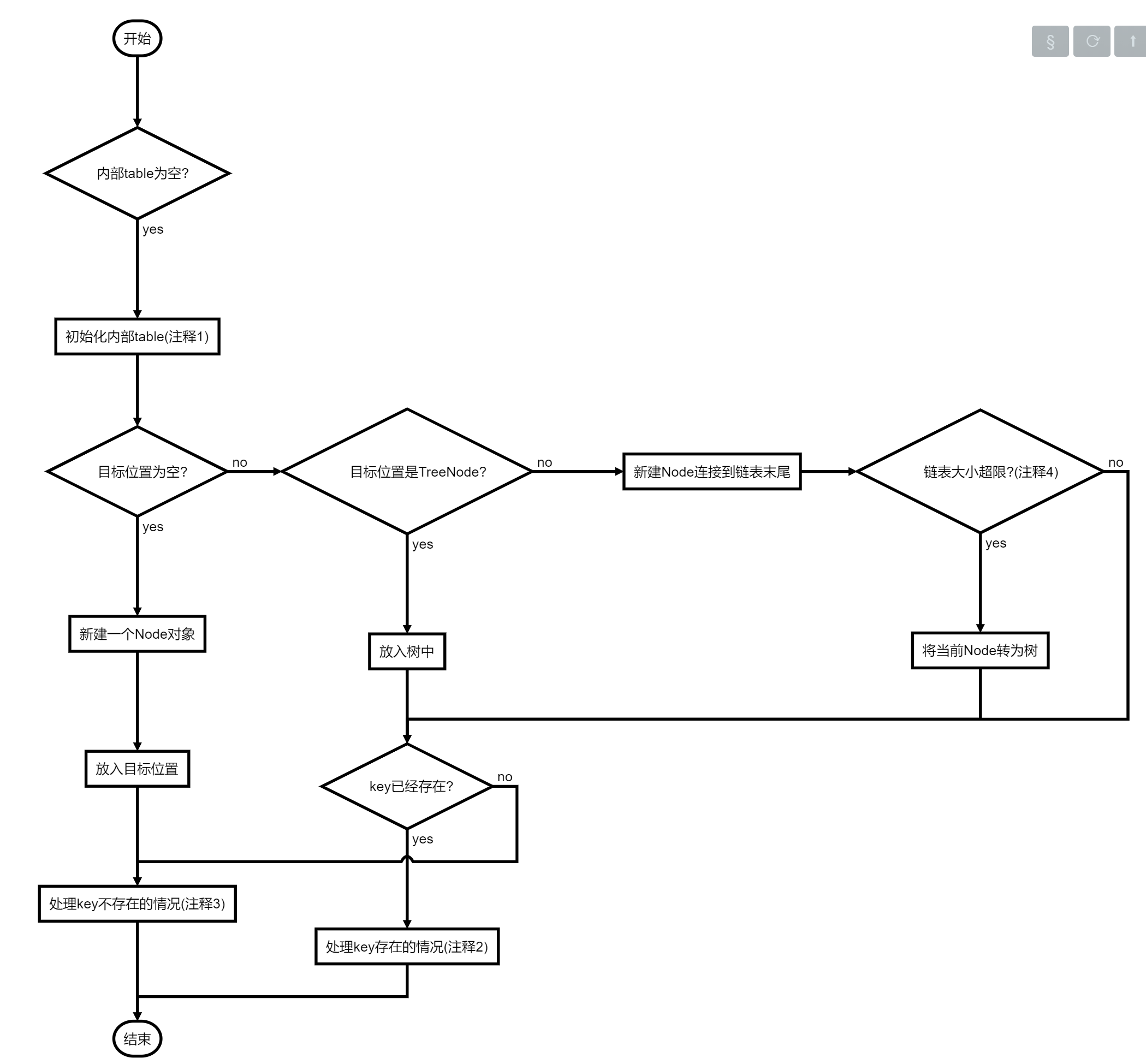
- 内部table的初始化:调用resize方法来进行table初始化及相关threshold计算
- key已存在:返回值为原value
- key不存在:返回值为null
- Node转换成TreeNode:单个Node链长大于TREEIFY_THRESHOLD(默认为8)时进行尝试,当table大于MIN_TREEIFY_CAPACITY(默认64)时转换为树,否则仅仅进行扩容
2.2 删
删除的过程跟put大同小异,区别只在于,如果删除一个TreeNode,可能会造成树转化为BinNode,阈值根据树的形状为2或6,具体见红黑树部分
3. 扩容
扩容一共分为两步,第一步确定新的table大小和下次扩容阈值,第二步,重新将现有的table中的所有node存入新table(中间可能涉及TreeNode转链表Node)
3.1 计算table大小和下次扩容阈值

3.2 原table中的Node元素拷贝到新table
按新的容量初始化新table后,遍历原table的每一个Node,对于非null的Node,根据其Node类型,执行下列操作来复制到新的table
3.2.1 普通链表Node的复制
链表中的元素仅会发生下面两种情况:
- 向右移动
textile
hash 0000000010101
&cap-1 0000000001111
old_pos 0000000000101
hash 0000000010101
&newcap-1 0000000011111
new_pos 0000000010101 => 右移了16(等于oldCap)位- 原地不动
textile
hash 0000000001101
&cap-1 0000000001111
old_pos 0000000001101
hash 0000000001101
&newcap-1 0000000011111
new_pos 0000000001101 => 位置不动分别将上述两种Node按原顺序串成新链表,存入新table的对应位置
3.2.2 TreeNode的复制
通过调用 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap);方法放入新的两个位置
评论