知识图谱学习
什么是知识?
考虑这么一句话:我是中国人
主语:我
谓语:是
宾语:中国人
更进一步的抽象,可以认为上面这句话是图关系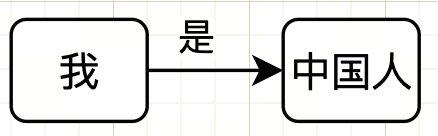
构建知识图谱
建模
设计
- 设计原则
- 业务原则:一切从业务逻辑出发,图谱设计本身体现业务逻辑,举例:用户是实体,订单是实体
- 效率原则:局部性,常用的数据放到知识图谱内部,不常用的关联到关系型数据库
- 分析原则:知识图谱内部只放跟分析相关的数据,不相关的放到其他存储(OLAP,NoSQL)
- 冗余原则:经常被关联查的冗余到知识图谱,但是注意一致性
- Schema定义
- 需要哪些实体?
- 包含哪些关系?
- 需要哪些属性?
- 哪些信息不在知识图谱的范畴里?
- 用户信息属于吗?
- 商品信息属于吗?
- 通用知识和商品信息的关系是什么?
- 实体定义
- 品牌
- 产品
- 成分
- 功效
- 禁用
知识抽取
公用医疗/健康知识
- UMLS
- SNOMED CT
- CUMLS
- 医药卫生知识服务系统
- 中医药知识图谱
- OpenKG
内部知识抽取
实体抽取
关系抽取
- 基于规则的模式匹配
- Node2Vec: 稠密低维向量
- BP神经网络拟合
- TRANSFORM
个人认为图谱的落地与搜索推荐息息相关。但在一些精准领域,例如金融和医疗,是比较难以构建的。个人在此推荐一种确认两个节点之间关系是否存在以及相关程度高低的方法:利用贝叶斯先验的思想,借用搜索引擎,输入两个待测节点,分析获取到的回传内容,从而判断两节点相关程度。可以有效地避免因人力不足而导致的数据准确度低的问题。
属性抽取
- 非结构化数据处理
- 长篇文本:NLP
- 图片:OCR+NLP
- 文件:数据格式转换
- 视频:?
知识融合
实体统一:同义词(ex:中国人==国人)
指代消解:下文里的她指代祖国
text我的祖国很强大,我很爱她
存储
基于RDF的存储
- 存储三元组
- W3C标准协议
- 易于交换
- 易于获取开放数据
- 不包含属性
- 学术界场景
- 典型实现:Jena
基于图数据库的存储
- 属性图
- 专有协议,专有实现
- 数据获取难度高
- 数据交换难度:版本、实现不同,无法交换
- 成本
- 典型实现:Neo4j
选型考虑因素
- 是否要选取图数据库
- 数据是否大到需要分布式存储
- 是否需要进行分级存储
- 是否对时态数据存储有一定的要求
- 是否需要支持知识推理
知识计算
知识计算主要是指在结构化的知识存储库中发现隐含关系以及知识,包括但不限于如下:
- 知识推理:产生式规则、基于谓词逻辑
- 图挖掘的相关技术:图遍历、最短路径查询、子图查询、路劲探寻
上层应用场景搭建
- 风控
- 不一致性验证
- 基于规则提取特征
- 基于模式的判断
- 可视化
- 查询/编辑
- AIML/D3JS
- 对话
- 基于概率:LLM,需要解决风控问题
- 基于规则:需要解决泛化问题
风险
输出什么样的内容是可接受的?怎么定义正确性?
- 似是而非的输出是不是可以接受?可以接受到什么程度?怎么衡量?怎么定义?
图谱结构随时间变化导致的知识图谱本身不稳定的风险
从图谱的变化中识别业务风险
医学知识的特点医学术语多样性:不同知识源对同一个概念采用了不同术语进行表达。比如:糖尿病又可称为消渴症、消渴、DM等。精度要求高:医学知识专业性强,医学应用场景容错率低,因此医学知识图谱的精确度要求高。复杂度高:医学是经验总结的科学,医学概念的内涵往往比较丰富,且有些医学知识复杂很难用简单三元组表达。
安全对齐和可控输出、长记忆问题
参考资料
- https://zhuanlan.zhihu.com/p/38056557
- https://www.zhihu.com/question/299907037
- https://mp.weixin.qq.com/s?__biz=MzU2MjM2OTY2Mw==&mid=2247483818&idx=1&sn=dfea60a9a98b57c24cee170dfc74ae6d&chksm=fc6bc4bacb1c4dacee7aea934c1d8944b3483d12e55d7ecff6274b1e8adadbe22d5ddd4122ec&token=2019272802&lang=zh_CN#rd
- Retrieval-augmented generation,chain of thought
- https://github.com/neo4j/NaLLM
评论